Matt Clancy wrote a typically wonderful post, this one about how proximity affects innovation. If you haven’t read that yet, go read it first.
I want to follow up on one sentence in particular: “To maximize discovery, you should group people who are unlikely to know each via other avenues, but who might plausibly benefit from being able to share ideas.” Based on the literature to-date, this seems absolutely right, and I’d like to “yes, and” it by saying that this seems like a perfect place for some economic engineering.
To be specific, I think there’s a fruitful research agenda to be had engaging with the above as a formal optimization problem. I’m quite bad at notation but I believe it would go something like this:
Given a laboratory floorplan with desks d ∈ D, and scientists s ∈ S, match each scientist to a desk mds ∈ {0,1} in order to maximize publication count U. Now of course the fun bits are that each pair of seats are a fixed distance apart, xd1d2 , and each scientist pair has some relevant attributes like, “are unlikely to know each other via other avenues, but who might plausibly benefit from being able to share ideas.” You might proxy these by, I don’t know, asking people who they already know, so something like ks1s2 ∈ {0,1}, and then if you want to be fancy grabbing some doc2vec representations of each person’s research field from their prior publications, which can just be like rs ∈ [0,1]. Finally, we have some functions relating publication count to these attributes, such that for each pair of scientists, their publication count is given by Us1s2 = f(x, k, r). E.g., we can relate prior ties k and walking distance x to publication count U through functions like the ones from Hasan and Koning in Matt’s post:
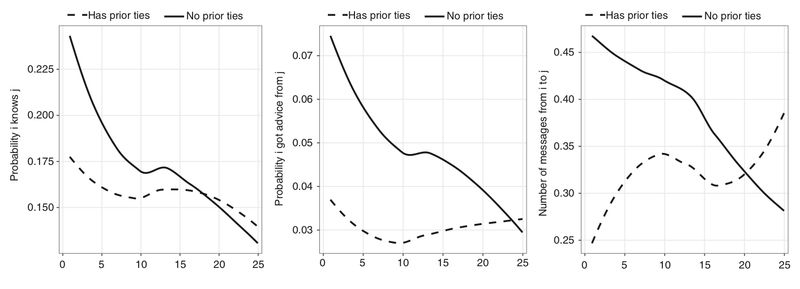
And then from Lane et al. (2020) we can relate each scientist pair’s research similarity (rs1 – rs2) to publication counts U with an inverted-U shape (haha, told you I was bad at notation), expressing that scientists who have very similar research shouldn’t sit close together, but rather they should have moderately similar research in order to boost collaboration:

With that all formulated, it’s just a matter of solving the combinatorial optimization problem. Also if you want I think you can cast the problem at the team-level instead of individual-level, but not much changes in the setup.
So the first point I would make is, as far as I know such an algorithm does not exist today, and it is non-trivial to formulate and solve! And I don’t think you could get as far as the above formulation without the foundational research from all the people mentioned in Matt’s post (Roche, Catalini, Oettl, Hasan, Koning, Miranda, Claudel, and more), but there’s still a big missing piece in not having such an algorithm expressed formally with some simulated (or even better, real-world) results, articulated in a research paper.
I don’t know if economists take it as given/trivial that someone will do it, but I don’t believe it is. If I was asked to solve this problem for a lab, I would say “wait a minute” and go grab the nearest PhD to do it instead. Why? Not only do I think the above formulation is beyond most people to set up and solve (including me), it’s the easy version! As Matt notes: 1) This is actually a dynamic problem, where the functions are probably nonlinear with respect to time, so right away we go from a single-shot solve (LP) to multi-timestep problem (DP, RL, what have you) 2) Looks like we can’t just use “distance between desks” because walking paths also matter, 3) And besides which in a real lab you have people coming and going all the time, which means stochasticity. So all in all, not trivial, and you could easily get a bunch of solid research papers just from making the problem progressively more realistic.
And then the second point I would make is, why I would call this an ‘economic engineering’ problem and not just a straightforward optimization problem, is we really aren’t settled on the dynamics, functions, or relevant variables yet. That is, there’s still causal inference work to do. So I think a proper research agenda around this problem actually looks like solving the optimization problem, then maybe ping-ponging back to a causal inference toolbox for a bit to find out what we’re missing in the formulation, and then updating the optimization algorithm with new, more correct functional forms or more relevant variables.
Anyway I’d quite like to see someone do this. Clearly there can be a lot of real-world value, and the literature so far has done great work in establishing some of the causal structure of the problem, but I don’t think it’s close enough to application such that entrepreneurs can take the existing research and make a useful product for lab managers. I think the research agenda above would still be foundational enough that it’s most appropriate for academia, and I think it would be necessary before we see impact of this literature out in the world.
